LDA线性判别分析
基本概念
线性分类: 指存在一个线性方程可以把待分类样本分离开,或者用一个超平面将正负样本分开,表达式为
$$y=w^\mathrm T+b$$
所谓超平面即是区分样本点的一个决策面,在二维世界中,可以理解为一条直线,如一次函数。
非线性分类: 指不存在一个线性分类能将样本分隔开,可以是一个曲面,也可以是多个超平面的组合。
LDA思想
核心思想:类内小,类间大
线性判别分析(Linear Discrimination Analysis, LDA)是一种监督学习的线性降维方法,即每个样本都是由类别的输出。其主要思想是”投影后类内方差最小,类间方差最大“,我们知道,对于一组数据来说,均值决定了它的中心,方差则是决定了这组数据的离散程度,越大越离散,越小越集中。在二分类问题中,我们将样本点在低纬度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,两种类别的数据点的中心尽可能的远离。
LDA算法的推导以及优化
LDA原理,投影到低纬度上的空间中,使得投影后的点会形成按类别区分一簇一簇的分布情况,相同类别的点较为集中,不用类别的点相聚较远。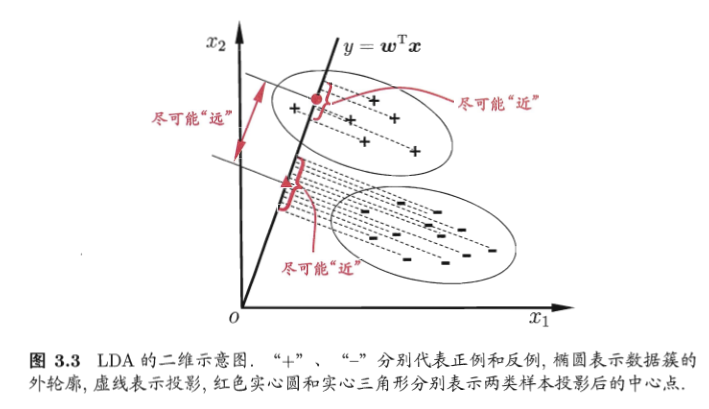
那什么是线性判别分析呢?所谓线性判别分析,就是将样本数据点投影到直线上,直线函数的解析式又称为线性函数,通常的表达式为:
$$y=w^\mathrm T$$
其中$w$表示特征向量,$x$表示样本列向量,$y$表示投影后的样本列向量。
首先对两类样本进行考虑分析,然后在推广到多维问题。
给定数据集$D=^m_{i=1},y∈(0,1)$,$X_i,\mu_i,\Sigma_i$分别表示$i\in{0, 1}$类示例的集合、均值向量、协方差矩阵。若将数据投影到直线$w$上,则两类样本的中心在直线上的投影分别为$ w^\mathrm T\mu_0$和 $ w^\mathrm T \mu_1$;若将所以样本点都投影到之想爱你上,则两类样本的协方差矩阵分别为$w^\mathrm T\Sigma_0w$和$w^\mathrm T\Sigma_1w$。
想要使得同类样本的投影带你尽可能地接近,可以让同类样本点的投影点的协方差尽可能的小,即$w^\mathrm T\Sigma_0w$+$w^\mathrm T\Sigma_1w$尽可能小;而若想要异类样本的投影点尽可能的远离,可以让类中心带你的距离尽可能的大,即$||w^\mathrm T\mu_0-w^\mathrm T\mu_1||$尽可能大,同时考虑即可得到待优化的目标:
$$J=\frac{||w^\mathrm T\mu_0-w^\mathrm T\mu_1||}{w^\mathrm T\Sigma_0w+w^\mathrm T\Sigma_1w}=\frac{w^\mathrm T(\mu_0-\mu_1)(\mu_0-\mu_1)^\mathrm Tw}{w^\mathrm T(\Sigma_0 +\Sigma_1)w}$$
定义类内散度矩阵(within-class scatter matrix)
$$
\begin{aligned}
S_w&=\Sigma_0+\Sigma_1\
&=\Sigma(x-\mu_0)(x-\mu_0)^\mathrm T+\Sigma(x-\mu_1)(x-\mu_1)^\mathrm T
\end{aligned}
$$
以及类间散度矩阵(between-class scatter matrix)
$$
\begin{aligned}
S_b =(\mu_0-\mu_1)(\mu_0-\mu_1)^\mathrm T
\end{aligned}
$$
所以待优化目标为
$$
J=\frac{w^\mathrm TS_bw}{w^\mathrm TS_ww}
$$
这就是LDA欲最大化的目标表达,即$ S_b $和$S_w$的“广义瑞利商”(generalized Rayleigh quotient).
如何求取$w$呢?
对于瑞利商来说,分子分母都是关于$w$的二次项,因此其解与$w$的长度无关,只与其方向有关,所以不妨令$w^\mathrm TS_ww=1$,则有:
$$
\begin{aligned}
\underset w min\quad -w^\mathrm TS_bw\
s.t. \quad w^\mathrm TS_ww =1
\end{aligned}
$$
由拉格朗日乘子法得到等价式
$$S_bw=\lambda S_ww$$
其中,$\lambda$是拉格朗日乘子。注意到$S_bw$的方向为$(\mu_0-\mu_1)$,令
$$S_bw=\lambda (\mu_0-\mu_1)$$
即可得
$$w=S_w^{-1}(\mu_0-\mu_1)$$
$w$的最大值就是矩阵$S_w^{-1}S_b$的最大特征值。
至此,投影面即可得到。
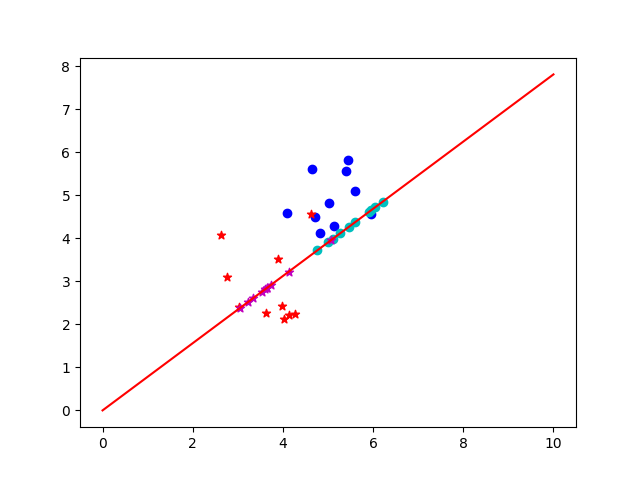
python实现以及结果展示
1 | import numpy as np |
结果展示如下